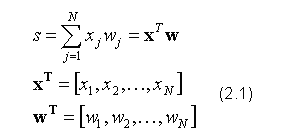
Jednokierunkowe, wielowarstwowe sieci neuronowe, czyli inaczej sieci typu MLP (ang. Multi-Layered Perceptron - wielowarstwowy perceptron), są najczęściej opisywaną i najchętniej wykorzystywaną w zastosowaniach praktycznych architekturą neuronową. Ich upowszechnienie związane jest z opracowaniem algorytmu wstecznej propagacji błędu (ang. Error Back Propagation), który umożliwił skuteczne trenowanie tego rodzaju sieci w stosunkowo prosty sposób. Oczywiście, od momentu opracowania, algorytm doczekał się licznych modyfikacji i ulepszeń, nie podważających jednak skuteczności pierwowzoru i stanowiących większe lub mniejsze modyfikacje jego podstawowej postaci.
Rozkwit prac nad sieciami neuronowymi, jaki obserwuje się od lat osiemdziesiątych jest także odpowiedzią na ograniczenia, jakie napotkano w badaniach i rozwoju systemów ekspertowych. Systemy ekspertowe mimo wielu osiągnięć w wąskich dziedzinach, okazały się nieprzydatne w przypadku szeregu problemów, z którymi umysł człowieka radzi sobie bez trudy, a których nie można było imitować lub wyjaśnić w ramach wspomnianego kierunku badań nad sztuczną inteligencją. Zwrócono się wówczas w stronę analiz i prób naśladowania naturalnych struktur będących siedliskiem inteligencji, czyli budowy ludzkiego mózgu. Prace nad systemem bazującym na naturalnym pierwowzorze i określanym jako w pełni inteligentny, w połączeniu z upowszechnieniem się sieci wielowarstwowych i skutecznych metod ich uczenia, zaowocowały opracowaniem struktur o bardzo ciekawych właściwościach.
Wielowarstwowa sieć neuronowa jest w stanie przybliżać dowolnie złożone i skomplikowane odwzorowanie. Przy czym użytkownik nie musi znać lub zakładać z góry żadnej formy występujących w poszukiwanym modelu zależności, nie musi nawet zadawać sobie pytania czy jakiekolwiek możliwe do matematycznego modelowania zależności w ogóle występują. Cecha ta w połączeniu z samodzielną metoda uczenia się sieci neuronowej, czyni z niej niezwykle użyteczne i wygodne narzędzie do wszelkiego rodzaju zastosowań związanych z prognozowaniem, klasyfikacją lub automatycznym sterowaniem. Dodatkową zaletą jest duża tolerancja systemu neuronowego na uszkodzenia poszczególnych jej elementów, co podnosi niezawodność w sposób praktycznie niemożliwy do osiągnięcia w przypadku tradycyjnego oprogramowania, np. klasycznych systemów ekspertowych. Na tym nie kończy się lista zalet, równoległy model przetwarzania sygnałów wejściowych i stosunkowo prosta struktura nauczonej sieci neuronowej pozwala osiągnąć bardzo szybki czas reakcji, pozwalający na wykorzystywanie jej w zadaniach wymagających reagowania w czasie rzeczywistym.
Wszystkie wyżej wymienione czynniki, jak również rozpatrywanie sieci neuronowych jako próby przeniknięcia tajemnic ludzkiego mózgu, przyczyniły się do ogromnej popularności omawianej tematyki w ostatnich latach. Szacuje się że w roku 1998 średnio co pięć sekund pojawiała się na ten temat na świecie nowa publikacja lub nowe doniesieni konferencyjne, a liczba tytułów podręczników oraz monografii poświęconych sieciom neuronowym i wydanych do roku 1999 wyniosła 7 tysięcy pozycji.
Mimo swojej popularności sieci typu MLP są tylko jednym z wielu rodzajów struktur neuronowych, których tworzenie obejmuje wszelkie możliwe kombinacje dostępnych architektur i metod uczenia. W klasyfikacji niezliczonej ilości sieci neuronowych można wyróżnić cztery podstawowe kryteria związane z metodą trenowania, kierunkiem przetwarzania, postacią funkcji aktywacji neuronów oraz rodzajem danych wejściowych.
Wśród sposobów uczenia systemów neuronowych wyróżniamy sieci uczone bez nadzoru, które wymagają prezentacji jedynie danych wejściowych, oraz nadzorowane, korzystające z danych treningowych obejmujących wektor wejść oraz odpowiadający mu, prawidłowy i docelowy dla procesu uczenia, wektor wyjść. Ponadto metody uczenia można podzielić na algorytmy iteracyjne oraz procedury ustalające pożądane wartości parametrów w pojedynczym kroku.
Z punktu widzenia sposobu przetwarzania danych, sieci dzielimy na jednokierunkowe (ang. feedforward), przetwarzające sygnał począwszy od warstwy wejściowej i skończywszy na warstwie wyjściowej oraz architektury rekurencyjne (ang. feedback), mogące mieć postać zmodyfikowanej sieci wielowarstwowej, posiadającej pojedyncze połączenia neuronów wyjściowych z wejściowymi, lub sieci z pełnym sprzężeniem zwrotnym, w której wszystkie wyjścia z pojedynczej warstwy neuronów przesyłają sygnał ponownie na wszystkie wejścia tej samej warstwy.
Klasyfikacja o znaczeniu głównie historycznym wyróżnia sieci liniowe, wykorzystujące w neuronie liniową funkcje aktywacji oraz sieci nieliniowe, które właśnie dzięki nieliniowej postaci wspomnianej funkcji aktywacji neuronu stały się źródłem współczesnych sukcesów omawianej dziedziny.
Na koniec można wspomnieć o charakterze zmiennych wejściowych i wyjściowych. Obliczenia przeprowadzane w sieci neuronowej wymuszają posługiwanie się wyłącznie danymi ilościowymi, ale z uwagi na jakościowy charakter wielu zagadnień istnieje możliwość wykorzystania zmiennych o charakterze jakościowym lub lingwistycznym, które poddaje się w takiej sytuacji procesowi zakodowania do postaci liczbowej.
Przedstawione powyżej kryteria pozwalają na tworzenie dowolnych kombinacji klasyfikujących sztuczne sieci neuronowe. Oto jeden z możliwych podziałów obejmujący najbardziej znane systemy wraz z nazwiskami autorów i datami ich powstania:
Prace nad sztucznymi sieciami neuronowymi czerpią inspirację bezpośrednio z badań nad budową i funkcjonowaniem biologicznego systemu nerwowego, a zwłaszcza ludzkiego mózgu. Mózg jest największym w organizmie skupieniem komórek nerwowych, określanych także mianem neuronów. Ich liczbę szacuje się na ok. 10 miliardów. Poszczególne komórki posiadają średnio kilka tysięcy połączeń, co razem tworzy gigantyczną i niesłychanie skomplikowaną strukturę przesyłania i przetwarzania informacji. Osiągnięcia współczesnej neurologii pozwalają opisać części składowe mózgu wraz z przypisanymi im funkcjami. Najbardziej zewnętrzną i najmłodszą ewolucyjnie częścią półkul jest kora mózgowa, czyli cienka (1,5 - 4,5 mm) i pofałdowana sieć neuronów, odpowiadająca między innymi za takie przejawy inteligencji jak uczenie się, myślenie abstrakcyjne lub planowanie działań. Natomiast wewnątrz struktury mózgu, w części starszej ewolucyjnie, znajdujemy np. ciało migdałowate odpowiadające za reakcje czysto emocjonalne.
Podstawowym elementem biologicznego układu nerwowego jest neuron, czyli komórka przenosząca i przetwarzająca sygnały na drodze elektrochemicznej. W mózgu występuje wiele rodzajów neuronów, różniących się od siebie budową i pełnioną funkcją. Wyróżniamy np. neurony wzmacniające i tłumiące sygnał, a nawet ośrodki których pobudzenie wywołuje całe fale impulsów w dalszych komórkach. Na użytek modelu matematycznego, który jest pewnym praktycznym uproszczeniem komórki biologicznej, wyróżniamy w niej struktury odbierające sygnały o nazwie dendryty, element scalający impulsy z różnych wejść czyli perikarion, lub inaczej ciało komórki, oraz dłuższe włókno przesyłające sygnał wyjściowy do innych neuronów o nazwie akson. Akson jednej komórki łączy się z dendrytami kolejnych komórek za pośrednictwem szczeliny synaptycznej. W biologicznym oryginale szczelina synaptyczna, czyli inaczej synapsa, wypełniona jest specjalną substancją nazywaną neurotransmiterem lub neuromediatorem.
Na drodze skomplikowanych procesów elektrochemicznych sygnał jest przekazywany z aksonu jednej komórki do dentrytu innej, ulegając podczas przechodzenia przez szczelinę synaptyczną istotnym modyfikacjom. Zgodnie z poglądami jednego z najbardziej znaczących badaczy systemów neurologicznych - Donlda Hebba - owa modyfikacja ma kluczowe znaczenie dla procesu uczenia się. Sposób w jaki synapsa przekształca przekazywany sygnał, czyli siła połączenia synaptycznego, ulega w procesie uczenia zmianom, polegającym na wzmacnianiu zdolności do przekazywania sygnałów pożądanych. Sygnały wejściowe odebrane za pośrednictwem dendrytów przekazywane są następnie do ciała komórki, gdzie ulegają scaleniu. Jeżeli łączny sygnał obecny w perikarionie przekroczy pewną wartość progową, neuron przechodzi w stan aktywności lub inaczej zapłonu i generuje za pośrednictwem aksonu sygnał wyjściowy.
Układ opisanych wyżej w dużym uproszczeniu elementów i suma dokonywanych przez neurony operacji logicznych stanowi podstawę i siedlisko ludzkich zachowań inteligentnych oraz świadomości, przy czym efektywność szczelin synaptycznych jest obszarem, w którym zapisana jest cała wiedza systemu.
Matematyczny model neuronu biologicznego jest ogromnym uproszczeniem swojego naturalnego pierwowzoru. Siła połączeń synaptycznych reprezentowana jest przez wektor współczynników wag, przypisanych poszczególnym wejściom, a proces scalania ma postać iloczynu skalarnego wektora wejść z wektorem wag. Aby uzyskać efekt porównania ważonej sumy wejść z wartością progową, dodaje się kolejną zmienną wejściową i przypisuje jej pewną stałą wartość, na ogół 1. Wejście takie, określane często mianem "bias", podlega takiej samej procedurze trenowania jak pozostałe zmienne wejściowe. W trakcie procesu uczenia waga związana z dodawaną do każdej obserwacji stałą ulega odpowiedniej modyfikacji, dzięki czemu neuron jest w stanie uzyskać dowolną wielkość, odpowiadającą wartości progowej. Dodatkową zaletą przyjęcia takiej konwencji jest uzyskanie wygodnego zapisu w postaci jednolitego wektora wejść. Warto jednak wspomnieć, że dodawanie wartości stałej do zmiennych wejściowych nie zawsze jest stosowane, a w pewnych przypadkach jej pominięcie może prowadzić do uzyskania lepszych właściwości budowanej sieci neuronowej.
Procedura opisana powyższym wzorem (2.1) jest bardzo daleka od rzeczywistego przebiegu zjawiska, w którym tzw. potencjały postsynaptyczne podlegają złożonym procesom sumowania przestrzennego oraz czasowego. W omawianym modelu, ważona suma wejść przekazywana jest następnie do funkcji aktywacji, za pomocą której oblicza się wartość wyjściową sztucznego neuronu.
Rys. 2.1. Struktura sztucznego neuronu

Funkcja aktywacji może przybierać różne postaci. W pewnych przypadkach może mieć nawet formę tożsamości, co oznacza faktyczną rezygnację z użycia funkcji przejścia. Neuron pozbawiony funkcji aktywacji odpowiada liniowej funkcji regresji i dlatego jest w stanie przybliżać jedynie zależności liniowe. We wczesnych pracach nad sztucznymi sieciami neuronowymi chętnie wykorzystywano funkcję progową, w odmianie funkcji Heavisida:
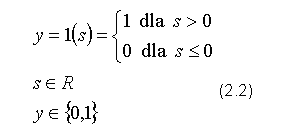
lub funkcji signum:
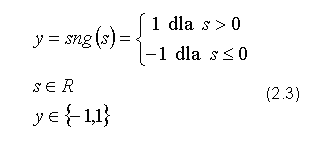
Na pierwszy rzut oka funkcja progowa wydaje się najlepszym odwzorowaniem biologicznego pierwowzoru. W praktyce jednak ograniczenie zbioru wartości funkcji do dwóch elementów uniemożliwia przybliżanie wartości ciągłych, a brak pochodnej i jej nieciągłość wyklucza użycie algorytmu wstecznej propagacji błędu. Także bliższa analiza i interpretacja procesów zachodzących w komórkach nerwowych podważa zasadność użycia powyższych funkcji. Neuron nie generuje pojedynczych bodźców ale serie impulsów. Skłania to do stwierdzenia że wartość wyjścia kodowana jest za pomocą chwilowej częstotliwości owych impulsów, a nie obecności lub braku pojedynczego bodźca, który w obliczu szumów występujących w biologicznej tkance nerwowej mógłby ulec stłumieniu. Przyjmując że częstotliwość impulsów może posiadać różne wartości, uzyskujemy w ten sposób uzasadnienie dla wykorzystywania w sieciach neuronowych wartości ciągłych.
We współczesnych zastosowaniach wykorzystuje się ciągłe funkcje aktywacji w postaci funkcji sigmoidalnej, będącej odmianą krzywej logistycznej:

lub tangensa hiperbolicznego:
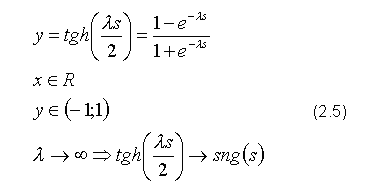
Parametr λ decyduje o kącie nachyleniu funkcji aktywacji i często jest pomijany, co jest równoznaczne z wartością λ = 1. Ciekawą właściwością powyższych funkcji jest fakt, iż przy l dążącym do nieskończoności funkcja sigmoidalna dąży do funkcji Haevisida, a tangens hiperboliczny do funkcji signum.
Obok przytoczonych przykładów wyróżnić można wiele innych form funkcji aktywacji, jak np. segmentową funkcję liniową lub funkcję Gaussa. W przypadku pracy z zakodowanymi zmiennymi jakościowymi zaleca się używanie funkcji aktywacji w postaci softmax. Jeżeli nie można określić granic przedziałów zmienności wyjść dopuszcza się nawet rezygnację z funkcji przejścia, a jeżeli nieznana jest jedynie górna granica wykorzystuje się funkcję wykładniczą.
Najczęściej spotykaną formą organizacji neuronów jest grupowanie ich w warstwy. Typowa struktura sieci typu MLP, nazywana siecią w pełni połączoną, zakłada istnienie takiej architektury połączeń pomiędzy neuronami, w której wszystkie wyjścia warstwy wcześniejszej połączone są z odpowiednimi wejściami każdego neuronu warstwy następnej. Oczywiście struktura naturalnych komórek w ludzkim mózgu sprawia wrażenie pozbawionej wszelkich restrykcji w zakresie połączeń. Przedstawiony schemat jest jednak o wiele wygodniejszy zarówno na użytek rozważań teoretycznych jak i implementacji w postaci programu komputerowego lub wytwarzania w formie układów elektronicznych. Nie istnieje także problem redukcji połączeń, który można rozwiązać przez nadanie odpowiednim współczynnikom wagowym stałej wartości równej 0. W całym bogactwie tworzonych sieci neuronowych nie brakuje także architektur zawierających połączenia pomiędzy neuronami z warstw nie sąsiadujących ze sobą.
W klasycznej terminologii sieci neuronowych wyróżnia się warstwę wejściową, jedną lub dwie warstwy ukryte oraz warstwę wyjściową. Warstwa wejściowa pobiera dane z otoczenia i przesyła je do pierwszej warstwy ukrytej. Jedyną funkcją warstwy wejściowej jest przesyłanie i rozprowadzanie sygnałów do pierwszej warstwy ukrytej. Jej neurony nie podlegają procesowi uczenia, nie posiadają wag, w których mogłaby być gromadzona wiedza o przybliżanych zależnościach i nie biorą udziału w procesie generalizacji. Następnie sygnał przesyłany jest na wejścia pierwszej warstwy ukrytej, która przetwarza dane i generuje sygnał wyjściowy podawany na wejścia warstwy kolejnej. Powyższy schemat powtarza się dla wszystkich kolejnych warstw ukrytych i kończy na warstwie wyjściowej, która zgodnie ze wzorcową architekturą oblicza wartości wyjść całej sieci i przekazuje je na zewnątrz. Warstwy ukryte oraz warstwa wyjściowa składają się z tego samego rodzaju neuronów, podlegających procesowi uczenia i na wzór komórki nerwowej, gromadzących wiedzę o przybliżanych zależnościach w wektorze wag.
Opisana wyżej konwencja jest dość myląca, rozbija ona bowiem warstwy neuronów wykonujących właściwe funkcje przybliżania i generalizacji na warstwy ukryte i warstwę wyjściową, co powoduje zamęt zarówno terminologiczny, jak i w zakresie liczenia owych warstw. Ponadto zdarzają się sytuacje wykorzystania tylko jednej warstwy podlegającej uczeniu, co powoduje całkowity brak warstw ukrytych. Dodatkowo, niektórzy badacze nie używają lub nie zaliczają do sieci neuronowej warstwy wejściowej, co zmusza do uznania za wspomnianą warstwę grupy elementów pełniących w klasycznym schemacie rolę pierwszej warstwy ukrytej. Całkiem osobnym problemem jest konieczność wstępnego przetworzenia, na ogół w formie przeskalowania, wartości zmiennych wejściowych. Mając też na uwadze fakt, że sieć używająca np. sigmiodalnej funkcji aktywacji, jest w stanie generować dane wyjściowe jedynie ze ściśle wyznaczonego przedziału, czyli (0; 1), przeskalowania prawie zawsze wymagać będą także wartości wyjść. Naturalnym miejscem dla wstępnego przetwarzania danych wydaje się warstwa wejściowa, a dla przeskalowania danych wyjściowych osobna, nie biorąca udziału w procesie uczenia i generalizacji, warstwa wyjściowa.
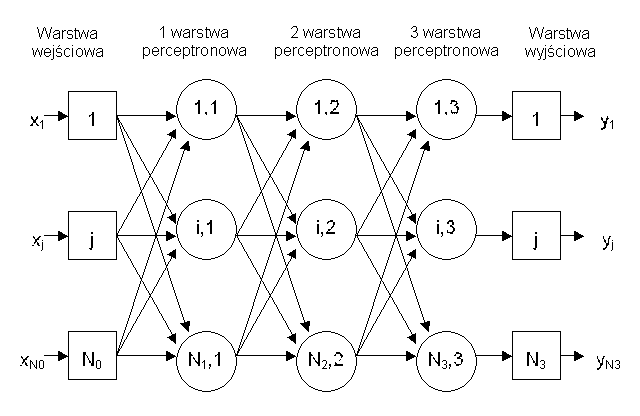
Z uwagi na powyższe argumenty oraz wygodę w numeracji i implementacji struktury sieci neuronowej, w pracy będzie wykorzystywana odmienna konwencja, zaprezentowana na zamieszczonym niżej schemacie (Rys. 2.2). W wykorzystanej konwencji wszystkie warstwy biorące udział we właściwych operacjach przybliżania i generalizacji będą traktowane jako kolejne warstwy perceptronowe, podczas gdy warstwa wejściowa oraz wyjściowa będą zajmowały się jedynie przesyłaniem sygnałów oraz, jeśli to konieczne, wstępną i końcową transformacją danych.
Rys. 2.2. Schemat struktury sieci neuronowej z trzema warstwami perceptronowymi oraz warstwą wejściową i wyjściową
Korzystanie z sieci neuronowej wiąże się na ogół nie tylko z określeniem odpowiedniego zestawu zmiennych wejściowych oraz wyjściowych i zgromadzeniem reprezentatywnego zbioru obserwacji, ale także, prawie zawsze, ze wstępną oraz końcową obróbką danych, podawanych do oraz uzyskiwanych z sieci. Wstępne przetwarzanie danych ma na celu usunięcie ze zbioru obserwacji cech niepożądanych, takich jak szumy, zakłócenia oraz błędy obserwacji, które zniekształcają rzeczywiste zależności występujące w zgromadzonych danych. W zastosowaniach technicznych, takich jak rozpoznawanie obrazów lub mowy, istotne znaczenie odgrywają metody filtrowania, pozwalające usuwać z obserwacji zakłócenia oraz cechy nieistotne lub niepożądane, takie jak np. różnice w jasności obrazów z poszczególnych klas.
W naukach społecznych, w tym w zastosowaniach ekonomicznych, wspominania obróbka surowych danych raczej nie znajduje zastosowania. Cechą typową dla gromadzenia i analizy obserwacji w tych dziedzinach jest z jednej strony niewielka liczebność danych statystycznych, a z drugiej brak jednoznacznej identyfikacji szumów i zakłóceń, które ze względu za wysoki stopień komplikacji badanych zależności, są trudne do odseparowania od zmienności charakteryzującej rzeczywiste własności badanych zjawisk.
Ważnym ograniczeniem metod neuronowych jest brak możliwości skutecznego generalizowania trendu, często spotykanego np. w szeregach czasowych. Ograniczenie to jest z jednej strony skutkiem korzystania z funkcji aktywacji o ściśle ograniczonym zakresie przyjmowanych wartości, a z drugiej wynika z faktu, iż w procesie uczenia kształt powierzchni funkcji odwzorowującej zmienne wejściowe na wyjścia sieci ulega zmianom w kierunku jak najlepszego dopasowania do prezentowanych wartości danych treningowych, co powoduje przyjmowanie przez nią trudnego do określenia kształtu na obszarach oddalonych od skupisk punktów wyznaczanych przez zbiór treningowy. W takiej sytuacji ekstrapolacja wychodząca poza wartości wyznaczane przez dane uczące nie może prowadzić do uzyskania wiarygodnych wyników. Prostym sposobem obejścia przedstawionego ograniczenia jest zamiana zmiennych zawierających trend na wartości względne, taki jak np. różnice lub stopy wzrostu.
Niekorzystnym zjawiskiem zbioru treningowego jest także nadmierna korelacja pomiędzy zmiennymi wejściowymi. Najczęściej stosowanym rozwiązaniem problemu korelacji jest wykorzystanie metody PCA (ang. Proncipal Component Analysis - analizy głównej składowej), znanej także pod nazwą transformacji Karhunena-Loevea. Technika ta polega na znalezieniu w n-wymiarowej przestrzeni zmiennych wejściowych m-tej liczby pierwszych głównych składowych, przy czym m << n. Prowadzi to do wyznaczenia ortogonalnych wektorów leżących w kierunku największej wariancji danych i pozwala uzyskać z dużej liczby skorelowanych wielkości znacznie mniejszy zbór słabiej skorelowanych zmiennych wejściowych.
Korzystając z sieci neuronowej typu MLP wyposażonej w sigmoidalne funkcje aktywacji koniecznie staje się również przeprowadzenie skalowania lub standaryzacji danych podawanych na wejścia sieci. Zgodnie z teorią, sieć typu NLP jest w stanie operować na surowych danych, w praktyce jednak brak odpowiedniej transformacji powoduje poważne zakłócenia w procesie uczenia oraz gorsze właściwości nauczonej sieci. Występowanie dużych różnic w zakresach wartości przyjmowanych przez zmienne, a tym samym w zakresach zmienności bezwzględnej może źle wpływać na działanie neuronu, zaburzając wpływ poszczególnych wejść. Duże wartości zmiennych wejściowych prowadzą także do nasycenia sigmoidalnej funkcji aktywacji, której pochodna w takim przypadku zbiega się do wartości 0, blokując tym samym proces uczenia. Sieci uczone w oparciu o opisywane zmienne są również bardziej podatne na utkwienie w minimach lokalnych funkcji celu.
Rozwiązaniem powyższych problemów jest najczęściej skalowanie zmiennych wejściowych względem odchylenia od wartości minimalnej do przedziału zmienności funkcji aktywacji. Skalowanie jest także prawie zawsze niezbędne w stosunku do wartości zmiennych wyjściowych sieci, ponieważ zakres wartości funkcji aktywacji, np. dla sigmoidy (0; 1), rzadko pokrywa się z zakresem wartości typowym dla konkretnej zmiennej wyjściowej. Zaprezentowane poniżej wzory pozwalają na skalowanie do przedziału (0; 1) - (2.6) oraz wykonanie operacji odwrotnej (2.7) i uzyskanie pierwotnego zakresu wartości zmiennej:
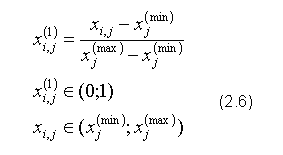

Alternatywą dla skalowania jest standaryzacja, występująca najczęściej w postaci odjęcia od zmiennej jej wartości średniej i podzielenia przez odchylenie standardowe:

Do innych typowych przekształceń danych wejściowych należy normalizacja, czyli dzielenie składowej przez normę wektora oraz różnego rodzaju transformacje nieliniowe. Zbiór danych treningowych może być także powiększany przez dodanie sztucznego szumu lub dołączenie sztucznych danych.
Klasyczny algorytm wstecznej propagacji błędu został spopularyzowany w wydanej w roku 1986 pracy Rumelharta oraz McClellanda i mimo upływy czasu nadal cieszy się dużą popularnością i jest chętnie wykorzystywany w praktycznych zastosowaniach. Źródeł wspomnianej popularności można się doszukiwać zarówno w jego względnej prostocie i łatwości przy implementacji, jaki i w fakcie, że jest on podstawą i punktem wyjścia wielu późniejszych metod.
Algorytm wstecznej propagacji błędu jest uogólnieniem reguły delta na potrzeby wielowarstwowych sieci neuronowych. Trenowanie sieci typu MLP jest w rzeczywistości numeryczną procedurą optymalizacji określonej funkcji celu, czyli problemem nad którym od dziesiątków lat pracują matematycy i statystycy. Należy on do tzw. metod gradientowych, które wykorzystują prawidłowość głoszącą, iż gradient funkcji wskazuje kierunek jej najszybszego wzrostu, a w przypadku zmiany znaków składowych na przeciwne, czyli pomnożeniu przez -1, kierunek jej najszybszego spadku. Właściwość ta pozwala na minimalizację funkcji celu przez modyfikację jej zmiennych, a w przypadku sieci współczynników wagowych, w kierunku najszybszego spadku funkcji, czyli zgodnie z regułą delty, proporcjonalnie do gradientu funkcji celu.
Funkcja celu sieci neuronowej może mieć różne postaci, w klasycznej jednak wersji używa się kwadratu błędu sieci, lub błędu średniokwadratowego, rozumianego jako różnica pomiędzy wartościami wyjść wygenerowanymi dla określonego wektora wejść, a wartościami wzorcowymi, czyli takimi do jakich sieć neuronowa powinna dążyć przetwarzając przyporządkowany do nich wektor wejść. W metodach uczenia sieci wielowarstwowych wyróżnia się dwie podstawowe techniki, modyfikujące nieznacznie sam algorytm i niektóre wzory. Należą do niech:

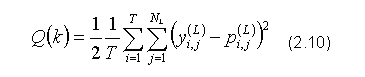
Algorytm wstecznej propagacji błędu sprowadza się do modyfikacji każdej z wag proporcjonalnie do wartości pochodnej cząstkowej funkcji celu. Modyfikacja wag w k-tej iteracji polega na odjęciu od wartości wag z iteracji poprzedniej (k - 1) wektora gradientu obliczonego dla bieżącej obserwacji. Algorytm jest sparametryzowany dzięki użyciu tzw. współczynnika uczenia, lub inaczej długości kroku, oznaczonego w poniższym równaniu symbolem α. Współczynnik uczenia przyjmuje na ogół wartości z zakresu od 0,5 do 0,9, ale w specjalnych przypadkach może nawet osiągać wartość α = 3:

Wektor gradientu, stanowiący kluczowy składnik powyższego wzoru (2.11), można przedstawić w postaci iloczynu pochodnej funkcji Q względem wyjścia j-tego neuronu z n-tej warstwy i pochodnej cząstkowej funkcji wyjścia tego samego neurony względem własnego wektora wag:
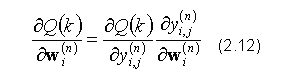
Powyższe wyrażenie (2.12) wygodnie jest z kolei przedstawić w formie sumy iloczynów pochodnych funkcji Q względem wyjść neuronów z warstwy następnej (n + 1) i pochodnych funkcji wyjść tych samych neuronów względem tych z ich wejść, do których trafia sygnał wyjściowy pochodzący z j-tego neurony warstwy poprzedniej (n-tej):

Analiza wyprowadzenia powyższego wzoru (2.13) ukazuje, że możliwe jest obliczenie pochodnej funkcji celu Q w stosunku do wyjść dowolnego neurony niezależnie od liczby warstw. Opisana procedura w praktyce przebiega w kierunku odwrotnym, od neuronów warstwy o numerze najwyższym do neuronu docelowego w warstwie o numerze niższym. W iteracyjnym wyznaczaniu kolejnych pochodnych wykorzystuje się wcześniej obliczone pochodne z warstw o wyższej numeracji i jedynym wyjątkiem od tej reguły jest pochodna funkcji celu Q po wyjściach ostatniej warstwy perceptronowej:

Finałowym elementem, niezbędnym do wyznaczenia potrzebnego w algorytmie gradientu, jest druga cześć iloczynu ze wzory (2.12), czyli pochodna wyjścia neuronu po jego wagach. Wykorzystując sigmoidalną funkcję aktywacji, która posiada względnie prostą pierwszą pochodną, potrzebny wzór ma postać:
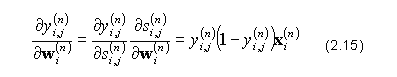
Użycie innej formy funkcji przejścia zmienia jedynie pierwszą cześć wyrażenia (2.15), należy jednak pamiętać że musi to być funkcja ciągła i różniczkowalna, co nie jest spełnione np. w odniesieniu do funkcji progowej.
Algorytm wstecznej propagacji błędu posiada niestety szereg słabości. Najpoważniejszą z nich jest brak gwarancji na osiągnięcie minimum globalnego funkcji celu. Procedura najczęściej prowadzi do osiągnięcia minimum lokalnego, które może okazać się wystarczająco głębokie i całkiem użyteczne w zastosowaniach praktycznych, ale również całkowicie bezużyteczne. Dlatego jedną z metod poszukiwania dobrych właściwości sieci jest wielokrotne ponawianie procesu uczenia w oparciu o losowo generowane zestawy wag startowych, na ogół z przedziału (-0,5; 0,5). Sam dobór początkowych wartości wag jest także problematyczny, gdyż zbył duże wartości wejść lub wag mogą doprowadzić do negatywnego zjawiska nasycenia funkcji aktywacji, praktycznie do postaci funkcji stałych, i braku postępów w procesie ucznia. Punkt startowy w przestrzeni wag ma duży wpływ na przebieg trenowania, ponieważ to od kształtu powierzchni funkcji celu w jego sąsiedztwie uzależnione jest ryzyko bardzo wolnej zbieżności algorytmu lub porażka utkwienia w płytkim minimum lokalnym.
Trudnym do rozstrzygnięcia problemem jest również określenie warunku zatrzymania algorytmu. Najprostszym kryterium jest osiągnięcie dopuszczalnego poziomu błędu dla wektorów generowanych przez sieć neuronową, oraz ustabilizowanie się wartości błędu w kolejnych iteracjach. Oczywiście podejmowane są liczne próby przezwyciężenia opisanych trudności, które owocują sporą ilością modyfikacji oraz odmian pierwotnej metody wstecznej propagacji błędu. Wspomniane pomysły pozwalają, na ogół za cenę dalszej komplikacji procedury, zniwelować większość problemów, ale nie są jednak w stanie usunąć podstawowych cech metod gradientowych, nie gwarantujących odszukania minimum globalnego funkcji celu.
Najpopularniejszą modyfikacją algorytmu propagacji wstecznej jest momentowa metoda wstecznej propagacji błędu, której główny pomysł sprowadza się do uzależnienia zmian wartości wag w bieżącej iteracji nie tylko od gradientu funkcji celu, ale także od zmiany tych samych wag w iteracji wcześniejszej. Omawiane rozszerzenie klasycznego algorytmu pozwala na względnie bezpieczne przyspieszenie procesu uczenia i częściowe zminimalizowanie ryzyka utknięcie w minimum lokalnym funkcji celu. Metoda dodaje do opisanego wcześniej sposobu modyfikacji wag drugi element, który jest zależny od parametru β, należącego do przedziału (0, 1]:

Uzależnienie procedury od zmiany wag w iteracji poprzedniej wprowadza do algorytmu element bezwładności, który zmniejsza chwilowe i gwałtowne zmiany kierunku wskazywanego przez gradient funkcji celu względem zestawu wag sieci. Powyższa właściwość wydaje się szczególnie korzystna w przypadku zastosowania metody uczenia przyrostowego, w której modyfikowanie wag po każdorazowej prezentacji pojedynczego wektora ze zbioru treningowego naraża cały proces na częste zbaczanie z głównej ścieżki minimalizacji. Utrzymywanie względnie stałego kierunku zmian w przestrzeni wag, zmniejsza tendencję do wchodzenia kolejnych zestawów ich wartości w płytkie minima lokalne. Dodatkową zaletą wprowadzenia opisywanej zmiany jest zdolność do znacznego przyspieszania procesu uczenie na obszarach tzw. płaskowyżu funkcji celu, czyli zakresu wartości w przestrzeni wag na którym występują minimalne wahania wielkości funkcji celu, a jej kształt można porównać do płaszczyzny. Można też wykazać analitycznie, iż dla typowej wartości β = 0,9, na idealnie płaskich obszarach funkcji celu, szybkość procesu ucznia może wzrosnąć nawet 10 razy.
W najprostszej postaci momentowego algorytmu wstecznej propagacji błędu przyjmuje się stałe wartości współczynnika uczenia oraz momentu. Trudno jednak określić ich optymalną wielkość, ponieważ są one zależne od napotykanego kształtu funkcji celu. W przypadku przechodzenia przez płaskowyż bardzo korzystna jest jak największa wartość zarówno współczynnika uczenia, jak i momentu. Nadaje ona procesowi trenowania rozpędu i pozwala skrócić czas jego trwania, podczas gdy mała wartość wspomnianych współczynników ma działanie odwrotne.
Niestety w przypadku natknięcia się na tzw. wąwóz, czyli obszar gwałtownych zmian wartości funkcji celu, przypominający kształtem strome zbocza wąwozu, zalecenia odnośnie optymalnych wartości współczynników ulegają częściowemu odwróceniu. W takiej sytuacji korzystna jest stosunkowo mała wartość obydwu stałych. Użycie zbyt wielkiej wartości współczynnika uczenia prowadzi do niemożności zejścia niżej, w dół wspomnianego wąwozu. Punkt wyznaczany przez wartości wag przemieszcza się w kolejnych iteracjach z jednej ściany na drugą, bez możliwości osiągnięcia pobliskiego minimum. Dobór wielkości współczynnika momentu jest jeszcze bardziej problematyczny, ponieważ pewna niewielka wielkość, pełni role filtru tłumiącego oscylacje jakie mogą wystąpić w wąwozie, ale jej nadmierny wzrost w pewnych urozmaiconych obszarach może spowodować niekorzystne odejście od linii najszybszego spadku minimalizowanej funkcji celu.
Duża cześć dalszych modyfikacji metody wstecznej propagacji błędu koncentruje się właśnie na odpowiednim doborze analizowanych współczynników. Dobór ich wartości opiera się zazwyczaj na algorytmach wykorzystujących kolejne gradienty funkcji celu i jest często sprowadzony do analizy pojedynczych wag. Usprawnienia pierwotnego algorytmu nierzadko faktycznie pozwalają skrócić proces uczenia sieci neuronowej, niestety na ogół pociągają one za sobą konieczność zaangażowania większych mocy obliczeniowych dla pojedynczego kroku, co razem z występowaniem typowych przypadłości pierwowzoru, często podważa pozorne korzyści ich użycia. Z pośród całej różnorodności technik za najbardziej efektywne i realnie zmniejszające niedomagania klasycznego EBP uważa się algorytm Quickprop opracowany przez Fahlmana w roku 1989 oraz RPROP (ang. Resilient Back PROPagation) z 1993 roku autorstwa Riedmillera i Brauna.
Do istotnych czynników wpływających na właściwości sieci neuronowej i jakość przybliżania zależności zawartych w prezentowanych danych treningowych należy także jej struktura, rozumiana zarówno jako liczba warstw perceptronowych, jak i ilość neuronów w poszczególnych warstwach.
Najprostszym rodzajem sieci perceptronowej jest pojedynczy neuron z tożsamościową funkcją aktywacji. Wspomniany element jest ściśle równoważny liniowej funkcji regresji, a jego współczynniki wagowe mogą być estymowane w sposób efektywny, bez ryzyka utkwienia w minimum lokalnym funkcji celu, przez metody używane przy budowie tradycyjnych modeli matematycznych, takich jak np. użycie estymatora MNK - Metody Najmniejszych Kwadratów. Ponadto, nie tworzy się wielowarstwowych sieci neuronowych zbudowanych z neuronów nie posiadających nieliniowości w funkcji aktywacji, ponieważ liniowa kombinacja transformacji linowych, może być przedstawiona za pomocą pojedynczej transformacji linowej, czyli dodawanie kolejnych warstw nie zmienia właściwości sieci:
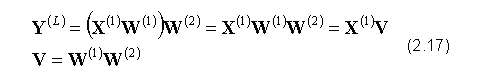
Biorąc pod uwagę neuron z najprostszą, nieliniową postacią funkcji aktywacji w formie odwzorowania Heavisida - 1(s), pojedyncza warstwa neuronów, czyli pojedynczy neuron, bowiem w sieci perceptronowej nie występują połączenia wewnątrz warstw, rozdziela przestrzeń wejść na dwie półprzestrzenie. Liniowa część funkcji zawartej w neuronie tworzy równanie płaszczyzny, określane jako rozmaitość liniowa stopnia n-1, lub w skrócie jako hiperpłaszczyzna. Pojedynczy neuron pełni rolę dyskryminatora liniowego, który jest w stanie odwzorować w przestrzeni wejść jedynie półprzestrzeń ograniczoną hiperpłąszczyzną. Jest to poważne organiczne, które uniemożliwia omawianej architekturze odwzorowanie, np. zależności typowej dla operatora logicznego XOR. Dodanie kolejnej warstwy neuronów umożliwia już odwzorowanie problemu XOR, a zgodnie z badaniami zawartymi w pracy Minskyego i Paperta dwuwarstwowa architektura sieci może odwzorować każdą transformację wejść binarnych. Pomijając ten szczególny przypadek, sieć typu MLP, zbudowana z dwóch warstw opisywanych wcześniej neuronów z progową funkcją aktywacji, jest w stanie odwzorować dowolny ograniczony lub nieograniczony obszar, wyznaczony przez fragmenty wielu hiperpłaszczyzn. Właściwość ta pozwala np. na odwzorowanie problemu XOR, ale nadal nie obejmuje możliwości wyznaczenia wszystkich dowolnych obszarów w przestrzeni wejść. Zbór punktów wyznaczony przez neurony drugiej warstwy musi być wypukły i jednospójny, co określa się nazwą simpleksu. Powyższe rozważania prowadzą do wniosku, iż użycie dwóch warstwa neuronów pozwala na przybliżanie większości, nawet bardzo złożonych zależności, ale dopiero użycie warstwy trzeciej gwarantuje możliwość odwzorowania dowolnego obszaru, czyli dowolnej zależności.
Oczywiście liczba warstw powinna być możliwie jak najmniejsza, ponieważ zwiększanie stopnia złożoności sieci neuronowej może łatwo doprowadzić do zjawiska nadmiernego dopasowania wag do punktów ze zbioru treningowego, przy jednoczesnym braku zdolności do generalizacji i odwzorowania zawartych w zbiorze zależności. O stopniu złożoności sieci typu MLP świadczy, obok liczby warstw, ilość wykorzystywanych w poszczególnych warstwach neuronów. Poszukiwanie optymalnej struktury sieci oznacza nie tylko dążenie do uniknięcia nadmiernej złożoności, ale także nadmiernego uproszczenia sieci, gdyż w przypadku skomplikowanego charakteru struktury generalizowanego zjawiska, sieć może wykazywać tendencje do zbyt małego dopasowania swoich wag do prezentowanych zależności, co używając języka statystyki prowadzi do obciążenia estymowanych z jej pomocą wielkości.
Metody pozwalające wyznaczyć optymalną liczbę neuronów w warstwach obejmują:
Pomiar jakości działania sieci neuronowej jest niezbędny zarówno w procesie uczenia, jaki i w ocenie pracy już nauczonej sieci. Większość miar koncentruje się na obliczaniu błędu pomiędzy wartościami wzorcowymi, a wygenerowanymi dla tych samych wektorów wejść danymi wyjściowymi sieci. Najczęściej wykorzystuje się klasyczne i powszechnie używane statystyczne miary błędów, do których należą:
RMSE (ang. Root Mean Square Error) - pierwiastek błędu średniokwadratowego:
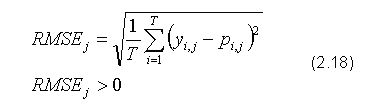
RMSPE (ang. Root Mean Square Percentage Error) - pierwiastek procentowego błędu średniokwadratowego:
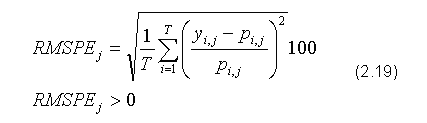
Mary związane z błędem średniokwadratowym wydają się najbardziej użyteczne w procesie uczenia sieci, ponieważ to właśnie funkcja oparta na błędzie średniokwadratowym, będącym podstawą zaprezentowanych powyżej miar, jest najczęściej minimalizowana w algorytmie wstecznej propagacji błędu.
ME (ang. Mean Error) - błąd średni:
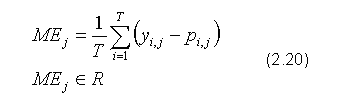
MPE (ang. Mean Percentage Error) - średni błąd procentowy:
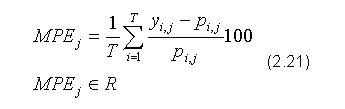
MAE (ang. Mean Absolute Error) - średni błąd absolutny:

MAPE (ang. Mean Absolute Percentage Error) - średni absolutny błąd procentowy:
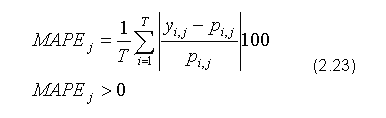
Pomiędzy miarami opartymi na błędzie średnim (ME, MPE) oraz średnim błędzie absolutnym (MAE, MAPE) istnieje zasadnicza oraz użyteczna różnica, wykorzystywana przy ocenie jakości prognoz modeli matematycznych i możliwa do zastosowania także w przypadku sieci neuronowej. Sieć neuronowa jest również rodzajem modelu matematycznego i mimo odmiennego, równoległego sposobu przetwarzania oraz szeregu innych właściwości, zapisanie jej w postaci tradycyjnego równania modelu matematycznego, chociaż skrajnie niewygodnie, jest możliwe.
Porównanie błędu średniego oraz absolutnego pozwala określić charakter rozbieżności pomiędzy zależnościami zawartymi w danych treningowych, a powierzchnią funkcji opisanej przez współczynniki wagowe sieci. W przypadku gdy wartości średnie błędu (ME, MPE) oraz absolutne (MAE, MAPE) są znaczne i do siebie bardzo zbliżone pod względem wartości absolutnej, wskazuje to iż wartości generowane przez sieć są systematycznie większe lub mniejsze od wzorców. W takim wypadku mamy do czynienia z poważnym rozchodzeniem się powierzchni tworzonej przez wektory wzorców z powierzchnią wektorów wyjść generowanych przez sieć. Wskazuje to na zbyt słabe dopasowanie sieci do przybliżanych zależności. W sytuacji przeciwnej, kiedy wartości błędu średniego są bliskie zeru, a błędu absolutnego wyraźnie wyższe, obserwujemy zjawisko różnokierunkowego odchylania się wartości wyjść sieci w stosunku do wartości wzorców. Opisana właściwość jest następstwem tendencji do znoszenia się błędów o znakach przeciwnych w miarach średnich i może np. wskazywać na zbyt uproszczoną strukturę sieci, które nie jest w stanie odwzorować bardzo złożonych zależności zawartych w danych ze zbioru treningowego.
Użyteczną odmianą miar błędu są także błędy procentowe, które pozwalają na porównywanie ze sobą różnych sieci. Należy jednak pamiętać, że w przypadku wzorców bliskich zeru dostarczana przez takie miary informacja staje się wadliwa.
Proces uczenia sieci neuronowej ma zgodnie z intencją prowadzić do odwzorowania zależności reprezentowanych przez zbiór uczący. Kształt powierzchni funkcji odwzorowującej w sieci neuronowej wektor wejść na wektor wyjść, jest modyfikowany za pomocą zmian wartości wag, w taki sposób by jak najlepiej odpowiadał faktycznemu kształtowi przybliżanej funkcji. W rzeczywistości jednak sieć neuronowa dopasowuje wartości swoich wag do obserwacji ze zbioru uczącego, które mogą zawierać zniekształconą lub niepełną informację o zależnościach zjawiska lub funkcji, które sieć stara się odwzorować. Ponadto sieć neuronowa uczona jest z myślą o zdolności do trafnego przybliżania wyjść odpowiadających tym punktom w przestrzeni wejść, które nie należą do zbioru treningowego, czyli do możliwości generalizowania.
Istnieje wiele przeszkód uniemożliwiających uzyskanie dobrej generalizacji sieci. Nie każdy problem może być rozwiązany przy wykorzystaniu struktur neuronowych, czego przykładem są np. generatory liczb pseudolosowych. Te z kolei które można rozwiązać w ten sposób wymagają wyboru odpowiedniego typu sieci oraz jej struktury, trafnego doboru zmiennych i odpowiedniej, reprezentatywnej próbki, czyli charakterystyki obserwacji w zbiorze treningowym. Ostatnim elementem decydującym o możliwości generalizacji jest przebieg procesu uczenia.
Nauczona sieć neuronowa może wykazywać zarówno zbyt małe dopasowanie swoich wag do zależności zawartych w zbiorze uczącym, jak i zbyt duże dopasowanie swoich parametrów do konkretnych punktów w przestrzeni wejść i wyjść. Przejawy niedostatecznego dopasowania, będące np. skutkiem zbyt prostej struktury sieci lub zbyt wczesnego przerwania procesu uczenia, można bez większych trudności dostrzec analizując miary błędów dla wyjść. Zjawisko nadmiernego dopasowania wag sieci do konkretnych obserwacji ze zbioru treningowego, określane jako przeuczenie sieci, prowadzi do występowania bardzo małych wartości błędów wyjść dla zbioru danych służących do modyfikacji wag, przy jednoczesnym braku zdolności do generalizowania, co przejawia się w błędnym przybliżaniu wartości wyjść, obliczonych dla danych wejściowych nie należących do powyższego zbioru.
Nie można więc bez wykorzystania dodatkowych metod określić czy sieć neuronowa trafnie generalizuje określone zależności, czy jej wagi zostały dopasowane jedynie do szumu zawartego w danych wykorzystanych do uczenia, oraz czy kształt opisanej przez nią funkcji nie ulega gwałtownym i nieuzasadnionym zaburzeniom w punktach pośrednich pomiędzy tymi ze zbioru treningowego. Ryzyko wystąpienia zjawiska przeuczenia jest niewielkie jeżeli liczba użytych obserwacji jest od 2 do 5 razy większa od liczby parametrów sieci, czyli wag, a praktycznie zerowe jeśli przewaga elementów zbioru uczącego sięga 30 razy. W przypadku jednak wykorzystania liczby obserwacji równej lub mniejszej od parametrów sieci, należy się spodziewać jego wystąpienia.
Rozwiązaniem problemu jest zastosowanie algorytmu wczesnego stopu (ang. early stopping), który zakłada podział zestawu treningowego na zbiory:
W metodzie wykorzystuje się sieć o dużej liczbie neuronów i małych losowych wartościach startowych wag. Proces uczenia jest kontynuowany do momentu, w którym błąd obliczany dla obserwacji ze zbioru testowego zaczyna wzrastać. Oczywiście każdy z podzbiorów pełnego zbioru treningowego musi być reprezentatywną próbką dla przybliżanych zależności.
Opisana metoda ma jednak szereg słabych punktów i uznawana jest za statystycznie nieefektywną. Podział pierwotnego zbioru treningowego prowadzi do tego, że ani uczenie, ani testowanie, ani końcowa estymacja błędu generalizacji nie wykorzystuje pełnej informacji zawartej w próbie. Nie ma jednoznaczności w kwestii metody podziału zbioru obserwacji, ani samego warunku zatrzymania, ponieważ wartość błędu może ulegać oscylacji. Powyższa metoda wydaje się jednak jedynym rozwiązaniem w przypadku posiadania nielicznej próbki, wymagającej przez wzgląd na skomplikowane, nieliniowe zależności użycia złożonej struktury sieci neuronowej.
Wielowarstwowe perceptronowe sieci neuronowe są najpopularniejszym rodzajem architektury neuronowej. Ich dynamiczny rozwój zapoczątkowany ponownie od lat osiemdziesiątych owocuje niezliczoną ilością zastosowań praktycznie w każdej dziedzinie. Mimo takiego rozpowszechnienia należy jednak podkreślić że sieć typu MLP jest jedynie pewną gałęzią badań nad systemami neuronowymi w ogóle, obejmującymi także struktury rekurencyjne, jednowarstwowe, czy uczone bez nadzoru.
Podstawowym elementem składowym każdej sieci jest neuron. Inspiracją dla tego bardzo prostego układu logicznego, podobnie jak i dla całej dziedziny zajmującej się sztucznym sieciami neuronowymi, są osiągnięcia współczesnej neurologii, badającej naturalne siedlisko ludzkiej inteligencji w postaci mózgu. Warto przy tym wspomnieć, że sieć typu MLP i jej neurony wydają się być najwierniejszą kopią biologicznego oryginału. Współczesne modele matematyczne neuronu prawie zawsze zawierają element nieliniowości w postaci ciągłej, nieliniowej funkcji aktywacji i to właśnie ta cecha umożliwia przybliżanie najbardziej nawet złożonych zależności. Sztuczne neurony tworzące sieć typu MLP grupowane są w warstwy, a następnie łączone ze sobą najczęściej metodą, w której każde wyjście jednej warstwy doprowadza sygnał do wejść wszystkich neuronów warstwy następnej. Klasyczna terminologia dotycząca warstw sieci jest dość myląca, dlatego wygodniej jest określić warstwy złożone z neuronów podlegających procesowi uczenia jako perceptronowe, w odróżnieniu od dodatkowej warstw wejściowej i wyjściowej, które służą przesyłaniu sygnałów i w których może, ale nie musi, zachodzić wstępna i końcowa obróbka danych.
Renesans sieci neuronowych jest w dużym stopniu efektem opracowania efektywnej metody uczenia sieci wielowarstwowych w postaci algorytmu wstecznej propagacji błędu. Sam proces trenowania jest w zasadzie numeryczną procedurą minimalizacji określonej funkcji celu i w przypadku wspomnianego algorytmu back propagation należy do rodziny metod gradientowych. Mimo iż obecnie opisano szereg innych algorytmów uczenia sieci neuronowych, cieszy się on nadal niesłabnącą popularnością, czerpiącą swoje źródła zarówno ze względnej prostoty jego stosowania, jak i braku metody która pozwoliłaby na całkowite wyeliminowanie jego słabości. Duża liczba opisanych sposobów uczenia to w rzeczywistości modyfikacje klasycznego algorytmu, z czego najbardziej znaną jest momentowa metoda wstecznej propagacji błędu.
O pożądanych właściwościach sieci neuronowej, do których należy przede wszystkim zdolność do generalizacji, nie decydują wyłącznie wartości wag neuronów. Uzyskanie odpowiedniego systemu neuronowego wymaga także prawidłowego doboru struktury sieci oraz bardzo często zabezpieczenia się przed wystąpieniem trudnego do wykrycia zjawiska przeuczenia. Mimo iż obecnie opracowano szereg technik budowy sieci oraz metodę wczesnego stopu, zabezpieczającą przed porażka przeuczenia, osiągane rezultaty często nie wydają się zadawalające. Sieci neuronowe typu MLP to niewątpliwie potężnie narzędzie z zakresu sztucznej inteligencji i z pewnością dominujący kierunek w pracach nad samymi strukturami neuronowymi. Ich rozwój i doskonalenie metod uczenia dokonuje się praktycznie na naszych oczach, podobnie jak ich upowszechnianie w zastosowaniach praktycznych.



