
Model ekonometryczny jest liczbowym, matematycznym odzwierciedleniem istniejącego w świecie rzeczywistym zjawiska lub zależności odnoszącej się do sfery gospodarki. Podstawowym wymogiem stawianym wobec każdego modelu jest konieczność wykazywania dużego podobieństwa względem wyróżnionych cech oryginału. Dzięki tej właściwości model może służyć do wyjaśniania i rozumienia badanych procesów oraz prognozowania ich dalszego rozwoju. Tworzenie klasycznego modelu ekonometrycznego obejmuje wykonanie szeregu standardowych kroków obejmujących: wybór zmiennych objaśnianych i objaśniających, określenie postaci analitycznej modelu, oszacowanie parametrów oraz analizę statystyczną zbudowanego modelu pod kątem podobieństwa do odzwierciedlanego zjawiska. Pierwsze dwa etapy wymagają podjęcia szeregu decyzji, które mogą być poparte dwoma rodzajami wiedzy. Prowadzi to do rozróżnienia modeli strukturalnych tworzonych w oparciu o strukturę wynikającą z teorii ekonomicznej oraz modeli regresyjnych, precyzyjnie określanych jako modele analizy regresji i korelacji, bazujących na informacjach pozyskanych ze statystycznej analizy obserwacji.
W przypadku gdy badany problem jest dobrze poznany, a występujące w nim zależności stosunkowo proste i oczywiste, ujęcie modelu w postaci tradycyjnych równań matematycznych wydaje się być rozwiązaniem najlepszym. Gdy jednak wiedza o charakterze modelowanych zależności jest nikła lub podejrzewa się, iż mają one bardzo skomplikowaną postać, precyzyjna specyfikacja postaci matematycznej może być niemożliwa i pojawia się wówczas konieczność wykorzystania innych narzędzi, takich jak np. sztuczne sieci neuronowe. Struktura neuronowa nie wymaga bowiem żadnych założeń odnośnie postaci analitycznej modelowanych zależności i jest w stanie przybliżyć każde, dowolnie nieliniowe odwzorowanie.
Zależności makroekonomiczne z reguły mają charakter silnie nieliniowe, a większość makrokategorii podlega wyraźnym oscylacjom. Teoria pozwala wyodrębnić zmienne wpływające na określone wielkości makroekonomiczne, ale podlega ona jednak ciągłemu rozwojowi, a dorobek poszczególnych kierunków myślowych w ekonomii często prowadzi do nieco innych wniosków i co za tym idzie innej postaci analitycznej proponowanych modeli. Uzasadnione wydaje się więc wykorzystanie na tym polu obliczeń neuronowych, które posiadają także dodatkową dla ekonomii zaletę, polegającą na braku sztywnych ograniczeń co do minimalnej liczebności obserwacji. Jest to istotne, ponieważ makroekonomia z reguły ma do dyspozycji próbki o niewielkiej liczebności, obciążone na ogół znacznymi zaburzeniami losowymi. Zastosowanie sieci neuronowej sprowadza się w zasadzie do wymiany narzędzi wykorzystywanych w procesie modelowania ekonomicznego. Specyfika takiego podejścia wymusza pewne modyfikacje w sekwencji kroków podejmowanych podczas budowy modelu, ale nie zmienia ogólnych zasad i głównego kierunku działań.
Prezentowany w tekście przykładowy model neuronowy w całości jest oparty na ekonometrycznym modelu gospodarki Szwecji o nazwie EMIL. Twórcami modelu są Prof. Jan B. Gajda z Uniwersytetu Łódzkiego oraz Prof. Claes-Hakan Gustafson z Uniwersytetu Örebro (Szwecja). EMIL należy do kategorii modeli strukturalnych i jego formuły oparte są na współczesnych teoriach makroekonomicznych.
Pierwsze równanie reprezentuję popytową stronę gospodarki, bazującą na założeniach modelu IS-LM, czyli równowadze pomiędzy dochodem i rynkiem pieniężnym. Równanie LM jest spełnione dla tożsamości dochodu (GDP) postaci:
Konsumpcja prywatna (CO) zależy od dochodu rozporządzalnego gospodarstw domowych, który jest funkcją dochodu całkowitego (GDP) i stopy podatków (t):

Na inwestycje prywatne brutto (INVGRO) wpływa realna stopa procentowa, obliczana jako różnica pomiędzy nominalną stopą procentowa (R) i oczekiwaną inflacją (INFLEXP). Cześć reinwestycyjna opiera się na opóźnionej zmianie w wartości dochodu (ΔGDP) oraz bieżącym zasobie kapitału (CAP):
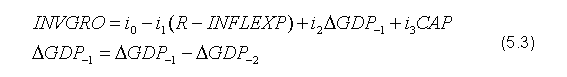
Oczekiwana inflacja (INFLEXP) obliczana jest jako średnia ważona rzeczywistej inflacji (P) z dwóch ostatnich okresów:
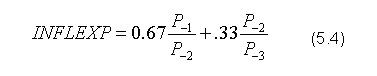
Wartość kapitału (CAP) bazuje na tożsamości zasobu kapitału z okresu poprzedniego pomniejszonego o jego zużycie w procesie produkcji i powiększonego o inwestycje (INVGRO). Jednak z braku wiarygodnych danych na temat wielkości zużycia kapitału, przyjęto że deprecjacja jest proporcjonalna do wartości kapitału (CAP) w okresie poprzednim:
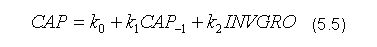
Eksport netto (NETEX) to różnica pomiędzy eksportem a importem. Jego wartość determinuje realny kurs waluty szwedzkiej w stosunku do koszyka walut (EXCHREA) oraz popyt zagraniczny (GDPFOR), który wpływa na eksport i popyt krajowy (GDP) wpływający na import:

Realny kurs waluty szwedzkiej wyznaczony jest na podstawie nominalnego kursu walutowego w stosunku do koszyka walut (EXCHNOM), zmodyfikowanego w oparciu o krajowy (P) i zagraniczny indeks cen (PFOR):
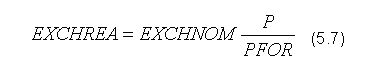
Równowagę na rynku pieniężnym określa formuła LM, wiążąca realną podaż pieniądza (MS / P) z wartością popytu (GDP) i poziomem rynkowej stopy procentowej (R). Rozwiązanie równości względem stopy procentowej prowadzi do prezentowanej poniżej zależności, której zasadność opiera się na założeniu, że rynkowe stopy procentowe, mimo iż ustalane decyzjami banków, są głęboko zakorzenione w wewnętrznych procesach zachodzących w gospodarce:

Po podstawieniu opisanych formuł do bazowej tożsamości dochodu (5.1), uproszczeniu i przekształceniu do postaci pierwszych różnic otrzymujemy pierwsze równie modelu EMIL, wyznaczające wartość zmiany popytu (ΔGDP):
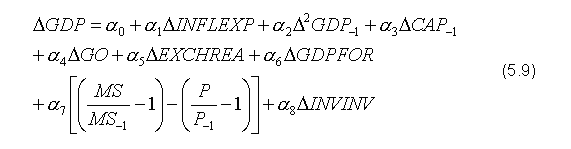
Drugą równością modelu jest dynamiczna funkcja podaży, która opisuje stopę zmiany cen objaśnianą przez stopę zmiany kosztów pracy, surowców i półproduktów. Koszty pracy wyrażone są za pomocą produktywności pracy (PROD) oraz nominalnego poziomu płac (WIND). Ponieważ założono że surowce i półprodukty są importowane, w równaniu znalazły się nominalny kurs waluty szwedzkiej (EXCHNOM) oraz poziom cen za granicą (PFOR). Wzrost cen zależy także od ogólnego poziomu aktywności gospodarki ujętego za pomocą produktu globalnego (GDP) i oczekiwanej inflacji (INFLEXP):
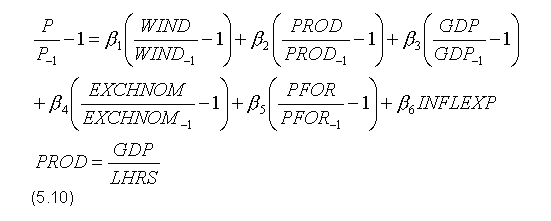
Trzecim równaniem jest funkcja eksportu netto (NETEX), będąca zmodyfikowaną wersja przedstawionej wyżej formuły (5.5). Do wyrażenia bazowego dodano realny poziom płac (WIND / P), by umożliwić w ten sposób odwzorowanie możliwości, zakładającej wpływ kosztów pracy na eksport netto bez modyfikacji cen produkcji, czyli bez oddziaływanie na realny kurs walutowy. Ostateczną postać równania uzyskano po przekształceniu wyrażenia do postaci pierwszych różnic:

Czwarta, ostania zależność modelu EMIL opisuje równowagę na rynku pracy (LHRS), wyznaczaną przez poziom płac realnych (WIND / P) i globalną produkcję (GDP). Ponieważ zatrudnienie może kształtować się odmiennie w sektorze prywatnym i państwowym, do formuły wprowadzono stosunek produkcji sektora prywatnego do produkcji globalnej (GDPPRIR / GDP). Po sprowadzeniu zmiennych do postaci pierwszych różnic funkcja przybiera postać:
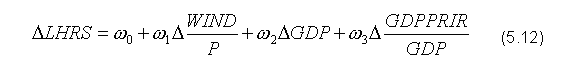
Wersja neuronowa modelu EMIL sprowadza modyfikację modelu wyjściowego głównie do rezygnacji z tradycyjnych równań matematycznych i ujęcia zależności makroekonomicznych w postaci struktur neuronowych oraz wykorzystania algorytmu trenowania sieci do wyznaczenia jej parametrów.
Pierwszy etap budowy modelu, czyli wyznaczenie zmiennych objaśnianych i objaśniających jest identyczny dla struktury w wersji neuronowej i tradycyjnej, co pozwala na skorzystanie z istniejącego zestawu zmiennych modelu EMIL. Etap drugi, czyli określenie postaci funkcyjnej przybliżanych zależności nie znajduje zastosowania, ponieważ siec neuronowa może aproksymować dowolne odwzorowanie. Twórca nie ma w tym przypadku możliwości wpływania na postać hiperpłaszczyzny funkcji parametryzowanej przez wagi sieci, której kształt określany jest automatycznie w procesie uczenia. Opisane właściwości podważają sens analizowania stabilności parametrów strukturalnych modelu i wprowadzania ewentualnych zmiennych zero-jedynkowych. W architekturze neuronowej nie sposób znaleźć parametry, które można by było określić mianem strukturalnych, ponieważ ogólna postać odwzorowania jest wypadkową oddziaływania dużej ilości wag sieci, których wpływ jednostkowy na wyjście, w przypadku tradycyjnej sieci typu MLP, jest praktycznie niemożliwy do zinterpretowania. Model neuronowy może odwzorować dowolną zależność, w tym także taką która zawiera zaburzenia odbiegające od ogólnego schematu problemu.
Wiele zmiennych makroekonomicznych wykazuje tendencję do stabilnych jednokierunkowych zmian w czasie, co prowadzi do budowy modeli tendencji rozwojowej. Sieć neuronowa nie jest w stanie odwzorować trendu i nie powinna być używana do przybliżania zależności, w których występują zmienne wykazujące wyraźną tendencję rozwojową. Wynika to po pierwsze z faktu, że wagi neuronów dopasowują się w procesie trenowania do obserwacji empirycznych i odwzorowanie realizowane przez taki mechanizm na ogół nie przechodzi przez punkty w przestrzeni wyjść, które wykraczają po za przedział zmienności zaprezentowanych jej obserwacji. Sieć neuronowa generuje ponadto wielkości z pewnego ściśle ograniczonego przedziału wartości, co oznacza brak możliwość wyjścia po za jego punkty graniczne.
Modelowane neuronowe wymaga więc wykonania dodatkowego kroku w postaci upewnienia się, że prezentowane sieci dane nie zawierają tendencji rozwojowej. W przypadku występowania trendu konieczne staje się odpowiednie przekształcenie zmiennych, np. do postaci pierwszych różnić lub stóp wzrostu. W przypadku EMIL wszystkie cztery ostateczne zależności makroekonomiczne modelu (5.9), (5.10), (5.11) i (5.12) operują na pierwszych różnicach lub stopach wzrostu, które nie wykazują tendencji rozwojowej. Nie ma więc w tym przypadku potrzeby ingerowania w postać zmiennych. Jeśli jednak podjętoby próbę modelowania pierwotnych tożsamości i równań funkcji popytu, czyli (5.1), (5.2), itd., konieczna była by odpowiednia transformacja np. GDP, którego poziom stabilnie i permanentnie wrasta z okresu na okres.
| Numer obserwacji | Rok | GDP (mld. SEK) | ΔGDP (mld. SEK) |
|---|---|---|---|
| 1 | 1966 | 825,00 | - |
| 2 | 1967 | 853,00 | 28,00 |
| 3 | 1968 | 884,00 | 31,00 |
| 4 | 1969 | 928,00 | 44,00 |
| 5 | 1970 | 988,00 | 60,00 |
| 6 | 1971 | 998,00 | 10,00 |
| 7 | 1972 | 1021,00 | 23,00 |
| 8 | 1973 | 1061,00 | 40,00 |
| 9 | 1974 | 1095,00 | 34,00 |
| 10 | 1975 | 1123,00 | 28,00 |
| 11 | 1976 | 1135,00 | 12,00 |
| 12 | 1977 | 1117,00 | -18,00 |
| 13 | 1978 | 1136,00 | 19,00 |
| 14 | 1979 | 1180,00 | 44,00 |
Zakres wartości generowany przez neurony ostatniej warstwy perceptronowej jest zdeterminowany przez zbiór wartości jakie może przyjmować użyta funkcja aktywacji. Wspomniany przedział, który dla funkcji sigmoidalnej wynosi (0; 1), rzadko pokrywa się z zakresem jaki przyjmują zmienne wyjściowe, co uniemożliwia wykorzystanie ich oryginalnych wartości w procesie uczenia. Opisana sytuacja dotyczy także zmiennych modelu EMIL, a rozwiązaniem tego problemu jest przeskalowanie danych do odpowiedniego przedziału, które można określić jako kolejny, dodatkowy etap budowy modelu neuronowego. W przypadku zastosowania rozwiązań opisanych we wcześniejszych rozdziałach i implementowanych w prezentowanej aplikacji o roboczej nazwie NeuralEngine v1.0, proces przeskalowania zmiennych egzogenicznych i endogenicznych wykonywany jest w osobnych warstwach wejściowej i wyjściowej. Wymaga on jednak podania minimalnego i maksymalnego poziomu każdej ze zmiennych, tak by wszystkie obserwacje należały do wymaganego przedziału wartości. W odniesieniu do omawianego modelu neuronowego, poziomy ekstremalne zostały wyznaczone przez wyszukanie największej i najmniejsze wartości dla każdej ze zmiennych, które następnie nieznacznie pomniejszono w odniesieniu do minimum oraz powiększono w przypadku maksimum:

Pominięcie ostatniego zabiegu i przyjęcie zakresu wyznaczanego bezpośrednio przez ekstrema oznaczałoby prezentowanie sieci zmiennych o wartościach 0 i 1, co grozi nasyceniem sigmoidalnej funkcji aktywacji i w efekcie niekorzystnym przebiegiem procesu trenowania.
Budowa systemu neuronowego oznacza pominięcie niektórych czynności typowych dla tradycyjnego modelu ekonometrycznego i jednocześnie wykonanie kilku dodatkowych kroków opisanych wyżej. Kolejnym wspólnym etapem dla obydwu wariantów modelu jest obliczenie wartości jego parametrów, które w przypadku sieci neuronowej oznacza przeprowadzenie trenowania, zakończonego wyznaczeniem wielkości wag neuronów.
Ostatnim podstawowym etapem jest analiza dopasowania modelu do przybliżanej zależności, koncentrująca się miedzy innymi na szacowaniu różnić pomiędzy wartościami teoretycznymi i empirycznymi zmiennych objaśniających, czyli błędów prognozy. W przypadku względnie prostego modelu ekonometrycznego istnieje na ogół możliwość analitycznego wyznaczenia oczekiwanego błędu prognozy, lub inaczej błędu predykcji, na postawie tych samych danych, które użyto podczas estymacji parametrów modelu. Z kolei wykorzystanie obserwacji nie biorących udziału w procesie szacowania parametrów prowadzi do wyznaczanie tzw. zrealizowanego błędu prognozy. Poziom komplikacji obliczeń zachodzących w sieci neuronowej uniemożliwia przy obecnym stanie wiedzy analityczne wyznaczenie oczekiwanego błędu prognozy, a szacowanie wspomnianego błędu na postawie obserwacji, które brały udział w procesie uczenia nie prowadzi do wiarygodnych wyników. Oczekiwany błąd prognozy można zawsze wyznaczyć za pomocą symulacji stochastycznej, jednak uzyskane w ten sposób wyniki nie dostarczają wiedzy na temat dopasowania modelu do przybliżanego problemu.
Sieć neuronowa podczas trenowania dopasowuje swoje wagi do prezentowanych jej obserwacji i dlatego wartości błędów oparte na tych samych danych nie dostarczają rzetelnej informacji na temat zdolności do generalizowania, w tym zjawiska przeuczenia, oraz stopnia dopasowania do aproksymowanej zależności. W celu wyznaczenia nieobciążonego błędu dopasowania należy podzielić cały dostępny zestaw obserwacji na zbiór treningowy oraz zbiór weryfikacyjny, który nie bierze udziału w uczeniu sieci i jest wykorzystywany do obliczenia zrealizowanego błędu prognozy. W opisywanym przypadku neuronowej wersji modelu EMIL z całej próby, liczącej 34 obserwacje roczne z lat 1966-1999, wydzielono zbiór weryfikacyjny stanowiący 15% całości i obejmujący 5 obserwacji. Wielkość zbioru służącego do oceny właściwości sieci jest kompromisem pomiędzy dążeniem do uzyskania względnie reprezentatywnego zbioru obserwacji i tym samym wiarygodnych ocen błędów dopasowania i generalizacji, a wymogiem zachowania jak największej ilości danych i tym samym informacji, w zbiorze biorącym udział w trenowaniu.
Wykorzystywana podczas wszystkich obliczeń aplikacja NeuralEngine v1.0, wymaga przygotowania przynajmniej dwóch plików tekstowych, zawierających zadany schemat struktury sieci oraz zestaw danych uczących.
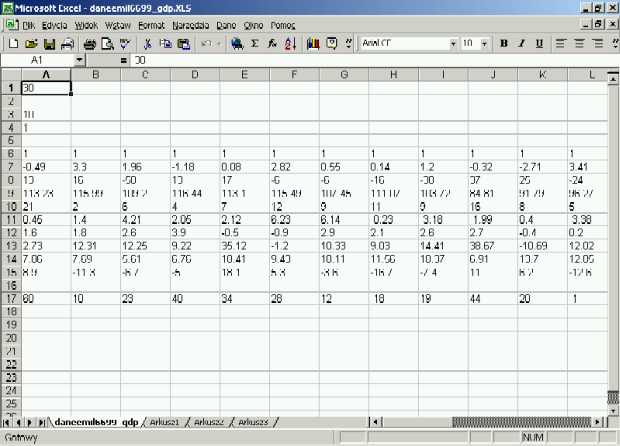
Rys 5.1 Przygotowanie struktury sieci dla programu NeuralEngine w arkuszu kalkulacyjnym Excel
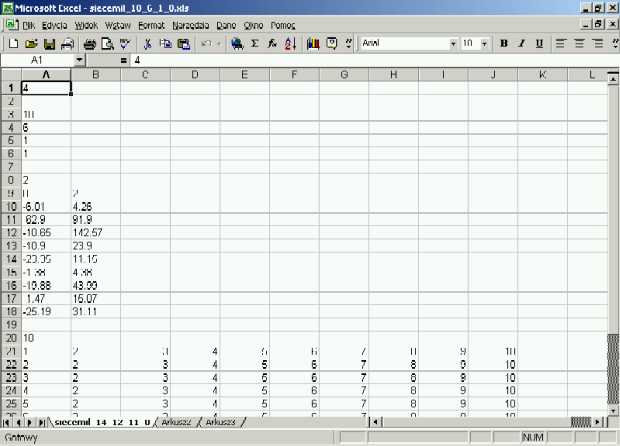
Wygodnym narzędziem do utworzenie wspomnianych plików jest arkusz kalkulacyjny, umożliwiający zapisywanie zawartości w formacie tekstowym. Układ danych musi być całkowicie zgodny z ustalonym formatem, co można uzyskać przez wpisanie każdej liczby i każdego komentarza w osobnych komórkach arkusza. Należy także pamiętać, że dane źródłowe i wynikowe programu NeuralEngine v1.0 posługują się anglojęzycznym oznaczeniem miejsc dziesiętnych, czyli kropką (np. -6.01). Na rysunkach przedstawiono przykładowe pliki ze strukturą sieci oraz obserwacjami stworzone w programie MS Excel. Przekonwertowanie zawartości okna do formatu tekstowego wymaga w tym przypadku zapisanie dokumentu jako "Tekst (rozdzielany znakami tabulacji) (*.txt)".
Rys 5.2 Przygotowanie obserwacji dla programu NeuralEngine w arkuszu kalkulacyjnym Excel
W rozdziale analizującym algorytmy uczenia sieci neuronowych przedstawiono przede wszystkim momentową metodę wstecznej propagacji błędu oraz jej modyfikację opartą na wykorzystaniu kosinusa kąta pomiędzy bieżącym gradientem minimalizowanej funkcji celu, a wcześniejszą poprawką wag neuronów. Korzyści jakie wynikają z wprowadzenia do wstecznej propagacji błędu współczynnika momentu są powszechnie uznane i dobrze opisane w literaturze przedmiotu. Dlatego też metoda momentowa została potraktowana w pracy jako podstawa i punkt wyjścia do dalszych rozważań nad możliwością poprawy efektywności procesu uczenia. Efektem teoretycznych spekulacji było zaproponowanie zmodyfikowanej odmiany algorytmu bazowego, wprowadzającej adaptacyjny mechanizm korygowania współczynników uczenia i momentu w oparciu o informacje dostarczane przez miarę kąta pomiędzy bieżącym gradientem minimalizowanej funkcji celu, a wcześniejszą poprawką wag. Konkretny przykład zastosowania makroekonomicznego sieci neuronowych, jakim jest neuronowa wersja modelu EMIL, pozwala sprawdzić w praktyce trafność powyższych założeń i faktyczną efektywność zaproponowanej odmiany algorytmu.
W eksperymencie wykorzystano sieć neuronową przybliżającą funkcję zmiany popytu (5.9), czyli pierwszego równania modelu. Wszystkie obliczenia wykonywano na komputerze klasy PC, wyposażonym w procesor o częstotliwości taktowania 1.3 GHz oraz pamięć RAM o pojemności 128 MB. Architektura sieci obejmowała dwie warstwy perceptronowe z 6 neuronami w pierwszej warstwie oraz jednym w drugiej (siecemil_10_6_1_0.txt). Jako główny warunek zatrzymania treningu ustalono osiągniecie wartości błędu na poziomie 1%. Główną miarą błędu wykorzystywaną podczas obliczeń w procesie uczenia jest zmodyfikowana miara RMSPE (ang. Root Mean Square Percentage Error), czyli pierwiastek procentowego błędu średniokwadratowego. Konieczność obliczania łącznego błędu wszystkich wyjść sieci wymusza użycie miary względnej, czyli błędu procentowego. Niestety błąd procentowy nie dostarcza wiarygodnych informacji w sytuacji gdy wartości zmiennych są bliskie zera. W celu wyeliminowania tej niedogodności błąd bezwzględny porównywany jest nie względem wartości wzorca, ale względem całkowitej zmienności wzorca dla określonego wyjścia, czyli różnicy pomiędzy jego wartością maksymalną i minimalną. Zmodyfikowana w ten sposób miara została oznaczone w wykorzystanej aplikacji NeuralEngine v1.0 jako RMSPE2.
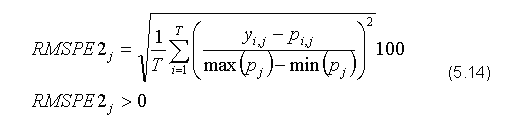
Raport o błędach generowany przez program wyszczególnia również miary MPE2 i MAPE2, które są modyfikacją standardowych miar MPE i MAPE, przeprowadzoną w sposób analogiczny do zaprezentowanego wyżej RMSPE2.
| Rodzaj zastosowanego algorytmu | Liczba iteracji | Czas uczenia (sekundy) | Czas trwania iteracji (sek.) | Błąd RMSPE2 |
|---|---|---|---|---|
| Momentowa metoda wstecznej propagacji błędu, uczenie przyrostowe | 15885 | 29,70 | 0,0019 | 0,99 |
| Momentowa metoda wstecznej propagacji błędu, uczenie wsadowe | 40795 | 51,20 | 0,0013 | 0,99 |
| Zmodyfikowana (kątowa) metoda wstecznej propagacji błędu, uczenie wsadowe | 2121 | 2,30 | 0,0011 | 0,99 |
Podczas testowania efektywności momentowej metody wstecznej propagacji błędu zastosowano dwie odmiany trenowania, czyli uczenie przyrostowe i wsadowe. Ilość obliczeń przypadających na jedną iterację w pierwszym przypadku wzrasta razem ze zwiększaniem liczebności obserwacji, powodując jednocześnie wzrost liczby modyfikacji wag przeprowadzanych w jednym kroku i spadek całkowej liczby iteracji w procesie optymalizacji. W przypadku uczenia wsadowego na każdy krok zawsze przypada jedna modyfikacja wag, co oznacza w praktyce wydłużanie się procesu trenowania w przypadku powiększania liczebności zbioru uczącego. Rezultaty eksperymentu w pełni potwierdzają powyższe tezy, średnia liczba wykonanych iteracji i całkowity czas trwania optymalizacji dla podstawowej metody momentowej jest wyraźnie wyższy w przypadku ucznia metodą wsadową, która wykazuje jednocześnie krótszy czas wykonywania jednego kroku.
Zmodyfikowany algorytm wstecznej propagacji błędu, oparty na wartości kata pomiędzy bieżącym gradientem funkcji celu, a ostatnią poprawką wag, okazał się jednocześnie zdecydowanie szybszy i wymagający mniej iteracji od wersji podstawowej w obydwu odmianach. Należy jednak dodać, że wykonuje on trenowanie w wersji wsadowej, co oznacza że wzrost liczby obserwacji w zbiorze uczącym zawsze będzie powodował jakiś spadek efektywności działania w stosunku do algorytmów wykorzystujących uczenie przyrostowe.
Po przetestowaniu efektywności trenowania zdecydowano się skorzystać ze zmodyfikowanej metody wstecznej propagacji błędu, opartej na wartości kąta pomiędzy bieżącym gradientem funkcji celu, a ostatnią poprawką wag. Każda z prezentowanych poniżej sieci neuronowych była trenowana pięciokrotnie, w celu przeanalizowania skuteczności zaproponowanych we wcześniejszym rozdziale różnych sposobów podziału i generowania danych uczących: Poszczególne kroki obejmowały:
W przypadku dwóch pierwszych metod zatrzymanie procesu uczenia następowało po osiągnięciu zadanego poziomu błędu RMSPE2, którego wartość ustalano w zakresie od 16% do 1%. Pozostałe metody kończyły wykonywanie iteracji, gdy błąd w zbiorze nie biorącym udziału w modyfikowaniu wag zaczynał permanentnie wzrastać. Trenowane zawsze było powtarzane wielokrotnie dla każdej z metod uczenia.
Podczas trenowania wykorzystano różne podzbiory danych, bazujące na 34 obserwacjach wielkości makroekonomicznych z lat 1966-1999. Zbiór wartości empirycznych, czyli zbiór danych uczących stanowił podstawę dla:
Przygotowanie podzbiorów obejmowało najpierw losowy podział zbioru uczącego na treningowy i weryfikacyjny, a następnie także losowe rozdzielenie zbioru treningowego na konstrukcyjny i testowy. Każdy przypadek trenowania był poprzedzony, jeśli było to potrzebne, operacją losowego podziału danych oraz generowaniem losowych wartości startowych wag i obserwacji interpolowanych. Wszystkie wykonywane działania, o ile nie jest to wyraźnie zaznaczone, wykorzystywały domyślne parametry komend programu NeuralEngine v.1.0.
Neuronowa wersja modelu EMIL składa się z czterech osobnych sieci neuronowych, przybliżających cztery finalne funkcje z wersji bazowej. Pierwsza sieć neuronowa aproksymuje odwzorowanie zmiany popytu o następującej postaci:

W niżej przestawionej tabeli zebrano najlepsze wyniki dla sieci neuronowej złożonej z 6 neuronów w pierwszej warstwie perceptronowej oraz jednego w drugiej (siecemil_10_6_1_0.txt), obejmujące wszystkie wymienione wyżej metody trenowania.
| Modyfikacja wag | Testowanie dopasowania | ME (mld.) | MAE (mld.) | MPE (%) | MAPE (%) | MPE 2 (%) | MAPE 2 (%) | RMSPE 2 (%) |
|---|---|---|---|---|---|---|---|---|
| zbiór treningowy | - | -2,13 | 6,57 | 2,57 | 23,33 | -4,96 | 15,29 | 16,11 |
| zbiór interpolowany | - | -1,90 | 3,23 | -6,15 | 10,45 | -5,43 | 9,25 | 10,06 |
| zbiór konstrukcyjny | zbiór testowy | -0,75 | 3,19 | -1,42 | 11,57 | -3,15 | 13,29 | 16,05 |
| zbiór treningowy | zbiór interpolowany | 0,34 | 13,92 | -62,24 | 139,91 | 0,45 | 18,08 | 21,90 |
| zbiór interpolowany | zbiór treningowy | -1,15 | 17,34 | -17,00 | 64,17 | -1,47 | 22,24 | 24,30 |
Najniższy błąd dopasowania RMSPE2 uzyskano dla metody opierającej modyfikowanie wag sieci wyłącznie o zbiór sztucznych obserwacji interpolowanych. Najgorsze dopasowanie do modelowanej zależności zaobserwowano w przypadku metod wczesnego stopu także używających zbioru interpolowanego. Sukces rozwiązania opartego na zbiorze interpolowanym może wskazywać na sytuację, w której dane posiadają dość znaczne zaburzenia losowe, obniżające efektywność sieci z wagami silnie dopasowanymi do obserwacji empirycznych, ale jednocześnie podział zbioru uczącego na zestawy konstrukcyjny i testowy prowadzi do uzyskania podzbiorów mało reprezentatywnych, obniżających tym samym efektywność algorytmu wczesnego stopu w wersji klasycznej. Prognozy jakie nauczona w ten sposób sieć wygenerowała dla zbioru weryfikacyjnego zawiera kolejna tabela.
| Numer obserwacji | Rok | Wartość empiryczna, ΔGDP (mld. SEK) | Prognoza sieci, ΔGDP (mld. SEK) |
|---|---|---|---|
| 2 | 1971 | 10,00 | 9,37 |
| 5 | 1974 | 34,00 | 29,88 |
| 17 | 1986 | 30,00 | 25,38 |
| 19 | 1988 | 31,00 | 34,33 |
| 29 | 1998 | 45,00 | 41,50 |
Druga sieć neuronowa jest odpowiednikiem dynamicznej funkcji podaży, zapisanej w postaci zależności stopy zmiany cen.

W niżej przestawionej tabeli zebrano najlepsze wyniki dla sieci neuronowej złożonej z 6 neuronów w pierwszej warstwie perceptronowej oraz jednego w drugiej (siecemil_7_6_1_0.txt), obejmujące wszystkie wymienione wyżej metody trenowania.
| Modyfikacja wag | Testowanie dopasowania | ME (mld.) | MAE (mld.) | MPE (%) | MAPE (%) | MPE 2 (%) | MAPE 2 (%) | RMSPE 2 (%) |
|---|---|---|---|---|---|---|---|---|
| zbiór treningowy | - | -0,09 | 0,30 | 221,72 | 221,73 | -0,67 | 2,20 | 3,39 |
| zbiór interpolowany | - | -0,11 | 0,43 | -1,60 | 7,03 | -1,16 | 4,57 | 5,98 |
| zbiór konstrukcyjny | zbiór testowy | 0,20 | 0,80 | -10,42 | 23,20 | 1,77 | 6,94 | 8,50 |
| zbiór treningowy | zbiór interpolowany | -0,57 | 0,67 | 130,41 | 145,12 | -4,90 | 5,78 | 6,32 |
| zbiór interpolowany | zbiór treningowy | 0,29 | 0,86 | 51,94 | 59,98 | 2,24 | 6,60 | 7,35 |
Najniższy błąd dopasowania RMSPE2 uzyskano dla klasycznej metody uczenia wykorzystującej jedynie zbiór treningowy. Najgorsze dopasowanie do modelowanej zależności zaobserwowano w przypadku metod wczesnego stopu używających zbioru interpolowanego. Prezentowana zależność oraz użyte dane wskazują na bardzo silny związek zmienności zmiennych objaśnianych ze zmiennością zmiennych objaśniających i niski poziom zaburzeń losowych. W takiej sytuacji daleko idące dopasowanie wag sieci do obserwacji okazuje się bardzo korzystne i lepsze nawet od metody wczesnego stopu, która w przypadku niezbyt licznych próbek może gubić cześć istotnych informacji o modelowanym zjawisku, traktując je jak przejawy szumu losowego. Prognozy jakie nauczona w ten sposób sieć wygenerowała dla zbioru weryfikacyjnego zawiera kolejna tabela.
| Numer obserwacji | Rok | Wartość empiryczna, stopa inflacji (%) | Prognoza sieci, stopa inflacji (%) |
|---|---|---|---|
| 23 | 1991 | 9,41 | 9,40 |
| 12 | 1980 | 13,70 | 13,83 |
| 5 | 1973 | 6,76 | 6,86 |
| 17 | 1985 | 7,46 | 7,74 |
| 30 | 1998 | -0,09 | -1,08 |
Kolejna, trzecia sieć neuronowa przybliża funkcję zmiany eksportu netto, zapisaną w formie:

W niżej przestawionej tabeli zebrano najlepsze wyniki dla sieci neuronowej złożonej z 12 neuronów w pierwszej warstwie perceptronowej oraz jednego w drugiej (siecemil_5_12_1_0.txt), obejmujące wszystkie wymienione wyżej metody trenowania.
| Modyfikacja wag | Testowanie dopasowania | ME (mld.) | MAE (mld.) | MPE (%) | MAPE (%) | MPE 2 (%) | MAPE 2 (%) | RMSPE 2 (%) |
|---|---|---|---|---|---|---|---|---|
| zbiór treningowy | - | 3,25 | 7,48 | -21,72 | 71,53 | 5,70 | 13,12 | 18,05 |
| zbiór interpolowany | - | 3,89 | 6,35 | -124,50 | 153,27 | 7,07 | 11,55 | 14,76 |
| zbiór konstrukcyjny | zbiór testowy | -1,43 | 3,90 | -∞ | ∞ | -4,09 | 11,15 | 12,52 |
| zbiór treningowy | zbiór interpolowany | -1,69 | 7,07 | -49,38 | 63,42 | -4,13 | 17,26 | 19,69 |
| zbiór interpolowany | zbiór treningowy | 2,79 | 4,93 | -31,43 | 41,30 | 5,36 | 9,49 | 13,23 |
Najniższy błąd dopasowania RMSPE2 uzyskano dla algorytmu wczesnego stopu wykorzystującego tradycyjny zbiór danych konstrukcyjnych podczas modyfikacji wag i zbiór testowy do oceny błędu dopasowania. Najgorsze dopasowanie do modelowanej zależności zaobserwowano w przypadku metod wczesnego stopu używających zbioru interpolowanego oraz klasycznej metody wykorzystującej wyłącznie zbiór treningowy. Sukces zatrzymanego uczenia w wersji podstawowej i słabe wyniki wykorzystania wyłącznie zbioru treningowego można tłumaczyć silnymi zaburzeniami losowymi danych, które uniemożliwiają dobrą generalizację zależności w przypadku nadmiernego dopasowania wag do obserwacji empirycznych. W przypadku uczenia o najlepszym wyniku RMSPE2 uzyskano także ogromne wartości błędów procentowych, które doprowadziły do przekroczenia zakresu liczbowego zmiennych w pamięci komputera i wygenerowania wyniku "nieskończoność". Uzyskane wyniki w praktyce ukazują mała wiarygodność błędów procentowych w przypadku danych o wartościach bliskich zera i zasadność użycia innych miar, jak np. MPE2, MAPE2 i RMSPE2. Prognozy jakie nauczona w ten sposób sieć wygenerowała dla zbioru weryfikacyjnego zawiera kolejna tabela.
| Numer obserwacji | Rok | Wartość empiryczna, ΔNETEX (mld. SEK) | Prognoza sieci, ΔNETEX (mld. SEK) |
|---|---|---|---|
| 2 | 1968 | -3,00 | -4,62 |
| 9 | 1975 | -14,00 | -11,81 |
| 20 | 1986 | 0,00 | -4,43 |
| 15 | 1981 | 21,00 | 13,71 |
| 11 | 1977 | 14,00 | 17,99 |
Ostatnia, czwarta sieć neuronowa aproksymuje zależność zmiany nakładu pracy, którą na potrzeby obliczeń neuronowych można zapisać jako:

W niżej przestawionej tabeli zebrano najlepsze wyniki dla sieci neuronowej złożonej z 12 neuronów w pierwszej warstwie perceptronowej oraz jednego w drugiej (siecemil_4_12_1_0.txt), obejmujące wszystkie wymienione wyżej metody trenowania.
| Modyfikacja wag | Testowanie dopasowania | ME (mld.) | MAE (mld.) | MPE (%) | MAPE (%) | MPE 2 (%) | MAPE 2 (%) | RMSPE 2 (%) |
|---|---|---|---|---|---|---|---|---|
| zbiór treningowy | - | -18,23 | 69,91 | -114,50 | 159,42 | -4,96 | 18,87 | 20,35 |
| zbiór interpolowany | - | 12,72 | 48,73 | -130,10 | 130,09 | 4,69 | 17,96 | 18,80 |
| zbiór konstrukcyjny | zbiór testowy | -14,98 | 36,54 | -14,05 | 43,42 | -5,52 | 13,46 | 16,62 |
| zbiór treningowy | zbiór interpolowany | -18,45 | 36,50 | -87,19 | 281,53 | -7,68 | 15,20 | 18,56 |
| zbiór interpolowany | zbiór treningowy | 28,66 | 65,51 | 51,73 | 243,41 | 7,62 | 17,43 | 21,98 |
Najniższy błąd dopasowania RMSPE2, podobnie jak w przypadku odwzorowania zmiany eksportu netto, uzyskano dla algorytmu wczesnego stopu wykorzystującego tradycyjnie zbiór konstrukcyjny i zbiór testowy. Najgorsze dopasowanie do modelowanej zależności zaobserwowano dla metod wczesnego stopu używających zbioru interpolowanego oraz klasycznej metody wykorzystującej wyłącznie zbiór treningowy. Poziom poszczególnych błędów był przy tym dość podobny co również może wskazywać na dużą losowość wartości modelowanego wskaźnika. Prognozy jakie nauczona w ten sposób sieć wygenerowała dla zbioru weryfikacyjnego zawiera kolejna tabela.
| Numer obserwacji | Rok | Wartość empiryczna, ΔLHRS (mln. godz.) | Prognoza sieci, ΔLHRS (mln. godz.) |
|---|---|---|---|
| 25 | 1991 | -146,1 | -119,02 |
| 13 | 1979 | 36,52 | 54,13 |
| 29 | 1995 | 125,23 | 80,19 |
| 19 | 1985 | 93,92 | 10,14 |
| 20 | 1986 | 36,53 | 45,73 |
Model ekonometryczny odzwierciedla fragment rzeczywistości gospodarczej, pozwalając na jego lepsze zrozumienie, wyjaśnienie i formułowanie prognoz na przyszłość. W przypadku dobrze poznanych zagadnień o jasno określonych, względnie prostych zależnościach, najlepszym rozwiązaniem jest ujęcie całości w formę równań matematycznych, odzwierciedlających powiązania strukturalne teorii ekonomicznej lub wyniki analizy korelacji. Zależności makroekonomiczne mają jednak na ogół charakter bardzo skomplikowany i wysoce nieliniowy, a wokół wielu problemów nadal toczą się dyskusje nie pozwalające na zakwalifikowanie ich do kategorii zjawisk dobrze i jednoznacznie poznanych. Ujmowanie problemów o takim charakterze w postaci tradycyjnych równań jest bardzo utrudnione i często pojawia się konieczność skorzystania z narzędzi takich jak np. sztuczne sieci neuronowe.
W pracy podejmuje się próbę zbudowania neuronowej wersji konkretnego modelu makroekonomicznego, przez zamianę narzędzi za pomocą których będą reprezentowane i szacowane zależności strukturalne ujęte w wersji bazowej. Punktem wyjścia i podstawą jest model gospodarki szwedzkiej o nazwie EMIL, składający się funkcji popytu, stopy inflacji, eksportu netto oraz zasobu pracy.
Budowa modelu neuronowego w swoich głównych założeniach nie odbiega od procesu tworzenia tradycyjnego modelu ekonometrycznego. W pierwszym podstawowym kroku, wspólnym dla modelowania w obydwu odmianach, należy określić zestaw zmiennych objaśniających i objaśnianych. Następny etap, polegający na zdefiniowaniu postaci analitycznej przybliżanych funkcji, nie znajduje zastosowania w przypadku struktur neuronowych. Sieć neuronowa sama określa w procesie uczenia postać realizowanego odwzorowania i praktycznie nie istnieje możliwość wyodrębnienia w typowej architekturze MLP wag będących odpowiednikami parametrów strukturalnych. Aproksymowana przez nią funkcja może być także dowolnie złożona i nieliniowa. W takiej sytuacji zbędne staje się analizowanie sieci neuronowej pod kątem stabilności parametrów strukturalnych i ewentualne wprowadzanie zmiennych zero-jedynkowych dla obserwacji odbiegających od ogólnego schematu.
Modelowanie neuronowe wymaga jednak dodatkowego kroku w postaci przeanalizowania wartości zmiennych pod kątem występowania tendencji rozwojowej. W przypadku stwierdzenia takiego zjawiska konieczna staje się odpowiednia, usuwająca trend obróbka danych. Wspomniana czynność może przesądzić o właściwościach sieci neuronowej, która nie jest w stanie odwzorować i generalizować zjawiska obarczonego tendencją rozwojową. Kolejny dodatkowy etap koncentruje się na wyznaczaniu przedziałów zmienności dla zmiennych zawartych w zbiorze uczącym. Specyfika obliczeń neuronowych, a szczególnie zakresy wartości wykorzystanych funkcji aktywacji, z reguły wymagają wstępnej i końcowej transformacji danych, najczęściej w formie przeskalowania bazującego na minimalnej i maksymalnej wartości zmiennej
Ostatni krok wspólny dla każdego modelu obejmuje analizę jego dopasowania do modelowanego zjawiska. Najbardziej wiarygodnym sposobem oceny zdolności do generalizacji struktury neuronowej jest wydzielenie z całego zestawu obserwacji empirycznych zbioru weryfikacyjnego, który jest następnie wykorzystywany do obliczania faktycznych wartości błędów.
Uczenie sieci neuronowych reprezentujących zależności makroekonomiczne modelu EMIL stworzyło okazję do porównania efektywności podstawowej oraz zmodyfikowanej odmiany momentowej metody wstecznej propagacji błędu. Wyniki eksperymentu potwierdziły korzyści wynikające z wprowadzenia do algorytmu adaptacyjnego mechanizmu modyfikowania współczynników uczenia i momentu, wykorzystującego informacje dostarczane przez miarę kąta pomiędzy wektorem gradientu funkcji celu, a wektorem ostatniej poprawki wag. Mimo że wersja zmodyfikowana, implementująca trenowanie wsadowe, wykazała znaczny wzrost efektywności, analiza teoretyczna wskazuje jednak na ogólny spadek efektywności trenowania metodą wsadową względem przyrostowej, w przypadku zwiększania liczebności zbioru uczącego.
Proces uczenia sieci neuronowych modelu EMIL obejmował sprawdzenie wszystkich zaproponowanych we wcześniejszym rozdziale sposobów generowania, podziału i wykorzystania danych podczas optymalizacji. Ogólny poziom wartości miar błędów był względnie porównywalny dla poszczególnych rozwiązań. Nie udało się jednak wyłonić metody najlepszej dla wszystkich aproksymowanych funkcji. W dwóch przypadkach najniższy błąd dopasowania do modelowanej zależności był efektem zastosowania algorytmu wczesnego stopu w tradycyjnej odmianie, wykorzystującej zbiory konstrukcyjny i testowy złożone z obserwacji empirycznych. W pozostałych przypadkach najefektywniejszą metodą okazało się wykorzystanie wyłącznie zbioru treningowego i wyłącznie zbioru sztucznych obserwacji interpolowanych. Wyniki wydają się potwierdzać tezę o zróżnicowanej przydatności różnych metod w zależności od stopnia w jakim dane obarczone są zaburzeniami losowym, a zawartość zbiorów uczących jest reprezentatywna w stosunku do opisywanego problemu. Dla sieci neuronowej przybliżającej funkcję stopy inflacji, której prognozy było najbardziej trafne a błąd najmniejszy, najlepsza okazała się metoda daleko idącego i niekontrolowanego dopasowania wag do obserwacji empirycznych. Z kolei w przypadku sieci wykazującej gorsze zdolności do generalizowania i większe błędy, czyli aproksymacji zasobu pracy i eksportu netto, wyraźnie najlepsza była metoda zatrzymanego uczenia oparta na danych empirycznych. Na koniec przypadek pośredni, czyli sieć neuronowa odpowiadająca funkcji popytu, została nauczona najlepiej pod względem zdolności do uogólniania na podstawie zbioru interpolowanego, który jest wynikiem obróbki danych niwelującej wpływ wartości nietypowych i odbiegających od ogólnego schematu.
GDP (ang. Gross Domestic Product) - Produkt Krajowy Brutto w cenach stałych z roku 1991 (mld. SEK).
CO (ang. consumption) - konsumpcja prywatna w cenach stałych z roku 1991 (mld. SEK).
INVGRO (ang. gross investment) - inwestycje prywatne brutto w cenach stałych z roku 1991 (mld. SEK).
GO (ang. government spending) - wydatki rządowe, czyli konsumpcja publiczna i inwestycje publiczne brutto, w cenach stałych z roku 1991 (mld. SEK).
INVINV (ang. inventory investment) - inwestycje w zapasy, czyli zmiana poziomu zapasów, w cenach stałych z roku 1991 (mld. SEK).
t (ang. taxes) - stopa podatków.
R (ang. interest rate) - nominalna rynkowa stopa procentowa. Średnia roczna stopa dyskontowa Riksbanken.
INFLEXP (ang. expected inflation) - oczekiwana inflacja.
CAP (ang. capital stock) - zasób kapitału, w cenach stałych z roku 1991 (mld. SEK).
P (ang. prices) - krajowy indeks cen towarów i usług konsumpcyjnych CPI, ujęty w stosunku do roku 1991.
NETEX (ang. export netto) - eksport netto, czyli eksport pomniejszony o import, w cenach stałych z roku 1991 (mld. SEK).
EXCHREA (ang. real exchange rate) - realny kurs wymiany waluty szwedzkiej w stosunku do koszyka walut.
GDPFOR (ang. foreign GDP) - popyt zagraniczny, obliczany jako średnia ważona wielkości realnego PKB w Niemczech, Wielkiej Brytanii I USA.
EXCHNOM (ang. nominal exchange rate) - nominalny kurs wymiany waluty szwedzkiej w stosunku do koszyka walut, czyli średnia ważona kursów walutowych w stosunku do DEM, GBP i USD. Jako wagi wykorzystano sumę szwedzkiego eksportu i importu w odniesieniu do krajów odpowiadających wymienionym walutom.
PFOR (ang. foreign prices) - indeks cen towarów i usług konsumpcyjnych CPI za granicą, ujęty w stosunku do roku 1991. Sposób obliczania wielkości jest analogiczny jak w przypadku EXCHNOM.
MS (ang. money supply) - M1, czyli podaż pieniądza obejmująca wartość gotówki (w tym wypadku wyłącznie banknotów) i wkładów na rachunkach czekowych (na żądanie).
WIND (ang. industry wage ) - nominalna płaca w przemyśle, jako stawka godzinowa w SEK.
PROD (ang. productivity) - produktywności pracy, czyli stosunek produkcji globalnej do nakładu pracy.
LHRS (ang. labor hours) - nakład pracy, czyli liczba przepracowanych godzin w mln.
GDPPRIR (ang. private GDP) - produkcja sektora prywatnego w cenach stałych z roku 1991 (mld. SEK).
PRIRRAT (ang. private to total GDP ratio) - stosunek produkcji wytworzonej w sektorze prywatnym do produkcji globalnej.